Example code
A fundamental feature of Locust is that you describe all your test in Python code. No need for clunky UIs or bloated XML, just plain code.
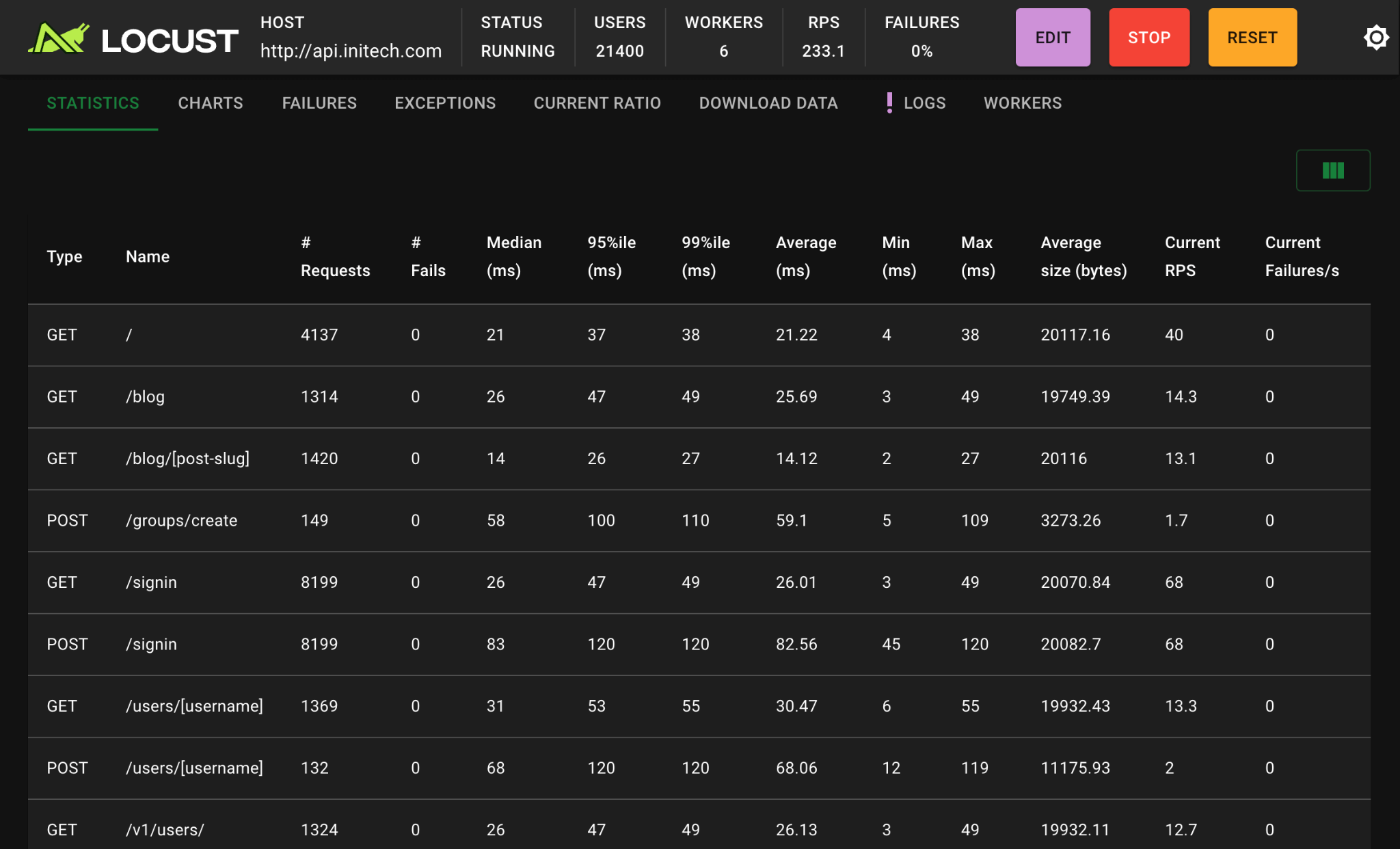
Define user behaviour with Python code, and swarm your system with millions of simultaneous users.
I'm impressed not more people talk about locust (http://locust.io/). The thing is awesome :) Shoutout too the guys from ESN :)
Armin Ronacher @mitsuhiko Author of Flask, Jinja2 & more
it’s become a mandatory part of the development of any large scale HTTP service built at DICE at this point.
Joakim Bodin @jbripley Lead Software Engineer at EA/DICE
locust.io is pretty fantastic, wish it had a bit more in the way of docs for non-HTTP stuff though
Alex Gaynor @alex_gaynor Django & PyPy core developer
from locust import HttpUser, between, task class WebsiteUser(HttpUser): wait_time = between(5, 15) def on_start(self): self.client.post("/login", { "username": "test_user", "password": "" }) @task def index(self): self.client.get("/") self.client.get("/static/assets.js") @task def about(self): self.client.get("/about/")
# This locust test script example will simulate a user # browsing the Locust documentation on https://docs.locust.io import random from locust import HttpUser, between, task from pyquery import PyQuery class AwesomeUser(HttpUser): host = "https://docs.locust.io/en/latest/" # we assume someone who is browsing the Locust docs, # generally has a quite long waiting time (between # 10 and 600 seconds), since there's a bunch of text # on each page wait_time = between(10, 600) def on_start(self): # start by waiting so that the simulated users # won't all arrive at the same time self.wait() # assume all users arrive at the index page self.index_page() self.urls_on_current_page = self.toc_urls @task(10) def index_page(self): r = self.client.get("") pq = PyQuery(r.content) link_elements = pq(".toctree-wrapper a.internal") self.toc_urls = [ l.attrib["href"] for l in link_elements ] @task(50) def load_page(self): url = random.choice(self.toc_urls) r = self.client.get(url) pq = PyQuery(r.content) link_elements = pq("a.internal") self.urls_on_current_page = [ l.attrib["href"] for l in link_elements ] @task(30) def load_sub_page(self): url = random.choice(self.urls_on_current_page) r = self.client.get(url)
# An example on how to use and nest TaskSets from locust import HttpUser, TaskSet, task, between class ForumThread(TaskSet): pass class ForumPage(TaskSet): # wait_time can be overridden for individual TaskSets wait_time = between(10, 300) # TaskSets can be nested multiple levels tasks = { ForumThread:3 } @task(3) def forum_index(self): pass @task(1) def stop(self): self.interrupt() class AboutPage(TaskSet): pass class WebsiteUser(HttpUser): wait_time = between(5, 15) # We can specify sub TaskSets using the tasks dict tasks = { ForumPage: 20, AboutPage: 10, } # We can use the @task decorator as well as the # tasks dict in the same Locust/TaskSet @task(10) def index(self): pass
A fundamental feature of Locust is that you describe all your test in Python code. No need for clunky UIs or bloated XML, just plain code.












The easiest way to install Locust is from PyPI, using pip:
> pip install locustRead more detailed installations instructions in the documentation.
Get the source code at Github.
We are working on a hosted cloud version of Locust. It's the simplest way to set up large-scale load tests with detailed reporting.
Check it out at locust.cloud

























